Alright so here we are with the beta 2 version which brings performance improvement to file loading and memory management. I've been able to speed up things by introducing processes in ICE Explorer. Why processes over threads ? For one thing because the GIL (Python Global Interpreter Lock) makes threading less powerful in python and makes full concurrency virtually impossible to achieve. For the particular problem of loading files, I find cooperating processes a lot easier to use and way faster than threading simply because you can execute more than one thing at the time using different processors.
Over the last few months or so I have been busy exploring processes, named pipes and shared memory. Mostly with PyQt but also with the python multiprocessing module. This module sure seems to work great on linux but after a few experimental scripts of my own, I have soon realized that it was quite challenging to use on Windows. I thought that going with PyQt for handling processes was a much better idea.
Processes
Using separate processes for loading files is really easy to achieve and makes full concurrency possible. The PyQt's QProcess class is used for running external python scripts through processes. Using QProcess is pretty straight forward: you call a start function to run a python script and a terminate function to ends it. You have a complete set of signals (callbacks) that you can use to get notified when a process state has changed (e.g. start, error, finish, read).
To manage multiple processes, an application needs something like a pool manager. Unlike python's multiprocessing module, PyQt doesn't have a process pool manager to handle jobs and processes. So I had to write my own pool manager for handling the processes used for loading and exporting files. Fortunately, this is not something difficult to write and was actually quite fun to do (to keep things simple my pool is loosely based on round-robin scheduling). In a nut shell, the main goal of a process pool manager is to dispatch a bunch of jobs (similar to workers in a thread analogy) through a set of processes. When a process is done with a job, it gets reused by the pool to run another job. This goes on and on until all jobs submitted to the pool manager are exhausted. For optimal results, the number of processes created by the pool manager usually matches the number of available cores on the machine.

For the purpose of loading files faster in ICE Explorer, a job is submitted to the pool manager for each file to load. So for an 8 core machine, you have 8 processes available to load a sequence of files. I figured that using 1 file (1 job) per process was more manageable and optimal as opposed to using N files per process which can lead to load-balancing problems when dealing with large files. You can still increment the number of processes used for loading or exporting files in ICE Explorer (through the preference dialog) but this is in general not as efficient.
Data sharing
Once processes are done loading the data, they need to notify the launching process (ICE Explorer) about the availability of new data sets. In PyQt, there are two ways that I know to achieve that: using a shared memory segment and IPC (inter-process communication).
Shared memory segment support is achieved with the QSharedMemory class. I have been using it to setup a shared memory buffer between the loader processes and ICE Explorer. QSharedMemory is straight forward to use too, but has a serious drawback: the memory must be allocated by the launching process, ICE Explorer itself. If you try allocating the memory in the loader process, PyQt will issue an error. This is very annoying as the memory size is only known by the loader process after the data has been read. For using a shared memory segment in this scenario, the buffer must be allocated in ICE Explorer, but since it has no idea what the size will be, it needs to allocate a huge memory block upfront (yes that's silly).
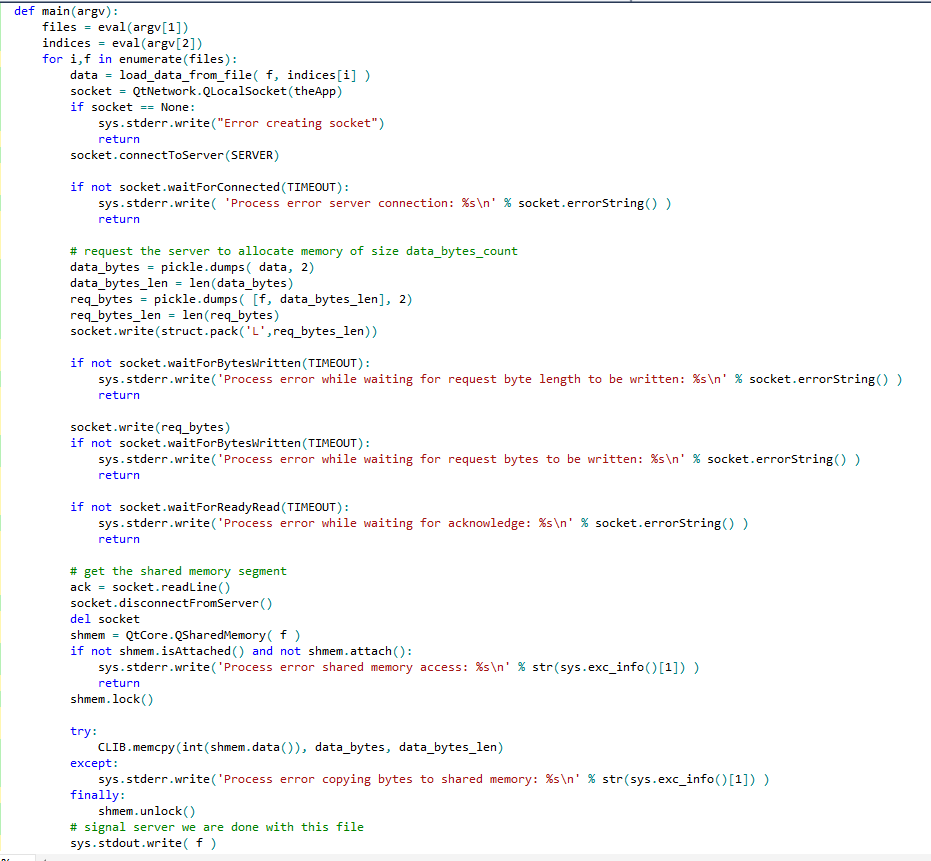
The second method I know for passing data back from process to process is IPC. Sockets are very popular among IPC protocols and PyQt has a rich set of socket classes. However, I find this protocol a bit difficult to master though. The simplest socket classes in PyQt are QLocalServer and QLocalSocket, which are basically the implementation of a named pipe. I used QlocalServer on the ICE Explorer side and QLocalSocket on the process side. One server per process. Each process is sending data to the QLocalServer port when done reading the file. The data is then dispatched by ICE Explorer to its different modules (viewer, browser, etc..). I thought that for large data size, sockets get unstable and difficult to manage. They are also not as fast as using a shared memory approach.
A simple mix
Combining these technologies for loading files makes things even more interesting and also more challenging programming wise. A named pipe can be used to send memory allocation requests to ICE Explorer from the loader process. Once the memory gets allocated by ICE Explorer, the process can copy the data to the shared memory buffer and makes it available to ICE Explorer. This strategy worked great. The loading speed was dramatically improved by about 6 times on a 64 bit machine with 8 cores.

HDF5
Another topic I have also addressed over the last month is the memory management issue that occurs when loading very large files in ICE Explorer. The challenge is to allocate most of the memory available without busting the system memory. This kind of problem is normally solved by using the operating system's memory mapping functions (e.g. python's mmap object). These functions are designed for mapping disk blocks into RAM, which helps saving lots of memory allocations. Unfortunately, you can't map compressed .icecache files to memory as they are not on the disk once they are uncompressed. This is where the HDF5 library comes into play.



So with this release, ICE Explorer can now load .icecache files with full concurrency and can load large files without falling in pieces when no memory is available. ICE Explorer can also convert a sequence of .icecache files to HDF5 format (.sih5) for faster loading. .sih5 files can also be loaded in ICE Explorer as well as in any HDF5 readers.
I hope this blog can somehow influence my pal at Softimage so he can come up with a new format 'a la HDF5' for caching ICE attributes. Hey we never know!
Have a nice day!
-mab

